


很多攻击手段都是通过脆弱的旁站和C段实现的,DDOS亦是如此,它可以导致服务器被占用资源甚至当机。这些攻击得以实施都是由于用户web服务器的真实ip暴露出去了。下面为大家揭秘黑客查找真实ip的多种方法。
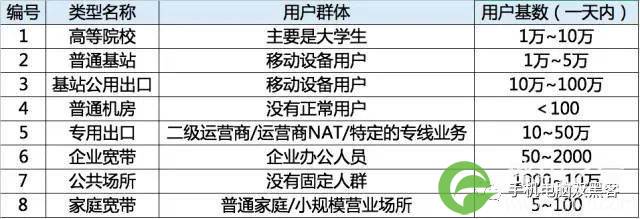
一、什么是CDN
首先,我们来认识下最寻常的真实ip隐藏的方法“CDN”。
内容分发网络(content delivery network或content distribution network,缩写作CDN)指一种通过互联网互相连接的电脑网络系统,利用最靠近每位用户的服务器,更快、更可靠地将音乐、图片、视频、应用程序及其他文件发送给用户,来提供高性能、可扩展性及低成本的网络内容传递给用户。
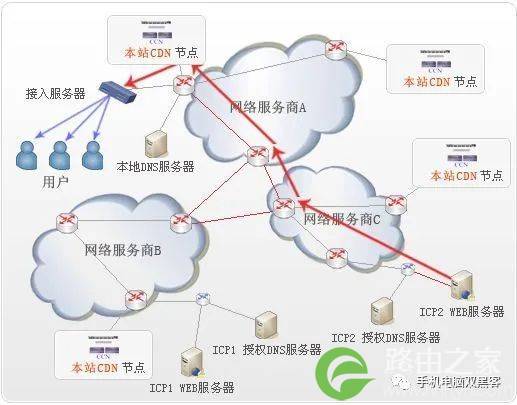
CDN节点会在多个地点,不同的网络上摆放。这些节点之间会动态的互相传输内容,对用户的下载行为最优化,并借此减少内容供应者所需要的带宽成本,改善用户的下载速度,提高系统的稳定性。国内常见的CDN有ChinanNet Center(网宿科技)、ChinaCache(阿里云)等,国外常见的有Akamai(阿卡迈)、Limelight Networks(简称LLNW)等;如下图,国内外主流的CDN市场格局:

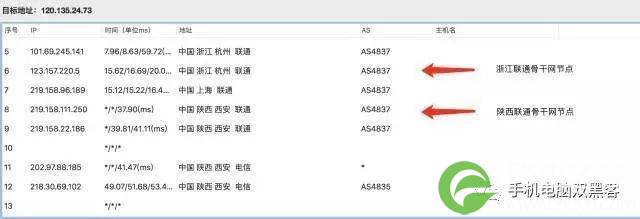
如图:用户先经由CDN节点,然后再访问web服务器。
二、如何判断IP是否是网站真实IP
1、Nslookup法
黑客一般nslookup想要查的域名,若是有多个ip就是用了cdn,多半为假ip;如图:

2、多地ping域名法
黑客也可以从多个地点ping他们想要确认的域名,若返回的是不同的ip,那么服务器确定使用了cdn,返回的ip也不是服务器的真实ip;
常用的网址有just ping:http://itools.com/tool/just-ping等等。

3、“常识”判断法
为啥叫“常识”判断法呢?
①.在反查网站ip时,如果此网站有1000多个不同域名,那么这个ip多半不是真实ip。常用的ip反查工具有站长工具(http://s.tool.chinaz.com/same)、微步在线(https://x.threatbook.cn/)等等。微步在线支持同服域名查询、子域名查询、服务查询、whois反查等,要注意的是,查询部分信息有次数限制,需先注册账号。
②.如果一个asp或者asp.net网站返回的头字段的server不是IIS、而是Nginx,那么多半是用了nginx反向代理,而不是真实ip。
③.如果ip定位是在常见cdn服务商的服务器上,那么是真实ip的可能性就微乎其微了。
三、如何寻找真实IP
1、子域名查找法
因为cdn和反向代理是需要成本的,有的网站只在比较常用的域名使用cdn或反向代理,有的时候一些测试子域名和新的子域名都没来得及加入cdn和反向代理,所以有时候是通过查找子域名来查找网站的真实IP。下面介绍些常用的子域名查找的方法和工具:
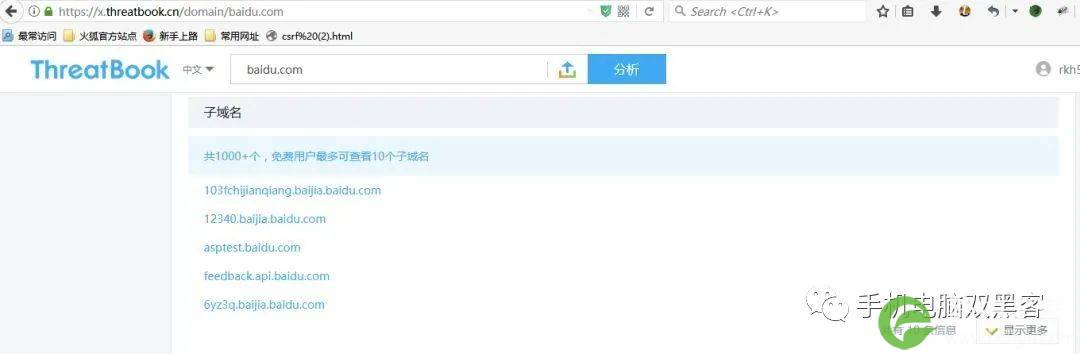
①、微步在线(https://x.threatbook.cn/)
上文提到的微步在线功能强大,黑客只需输入要查找的域名(如baidu.com),点击子域名选项就可以查找它的子域名了,但是免费用户每月只有5次免费查询机会。如图:
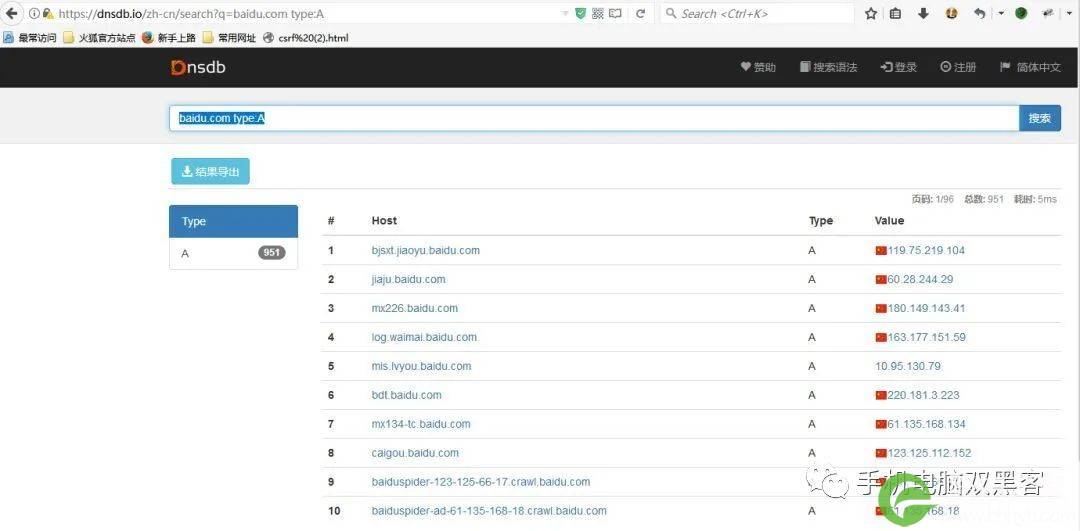
②、Dnsdb查询法。(https://dnsdb.io/zh-cn/)
黑客只需输入baidu.com type:A就能收集百度的子域名和ip了。如图:
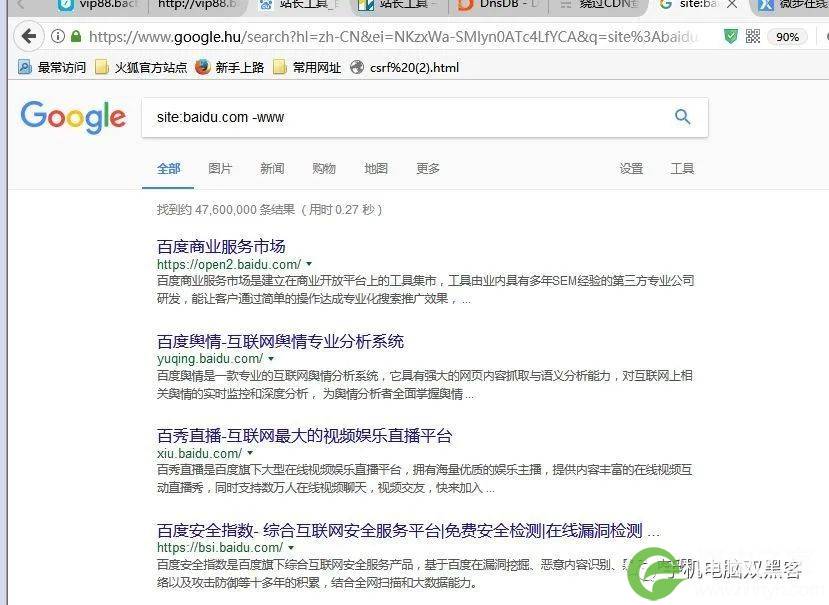
③、Google 搜索
Google site:baidu.com -www就能查看除www外的子域名,如图:
④、各种子域名扫描器
这里,主要为大家推荐子域名挖掘机和lijiejie的subdomainbrute(https://github.com/lijiejie/subDomainsBrute)
子域名挖掘机仅需输入域名即可基于字典挖掘它的子域名,如图:

Subdomainbrute以windows为例,黑客仅需打开cmd进入它所在的目录输入Python subdomainbrute.py baidu.com –full即可收集百度的子域名,如图:

总结:收集子域名后尝试以解析ip不在cdn上的ip解析主站,真实ip成功被获取到。
2、IP历史记录解析查询法
有的网站是后来才加入CDN的,所以只需查询它的解析历史即可获取真实ip,这里我们就简单介绍几个网站:微步在线,dnsdb.ionetcraft(http://toolbar.netcraft.com/),Viewdns(http://viewdns.info/)等等。
3、网站漏洞查找法
通过网站的信息泄露如phpinfo泄露,github信息泄露,命令执行等漏洞获取真实ip。
4、网站订阅邮件法
黑客可以通过网站订阅邮件的功能,让网站给自己发邮件,查看邮件的源代码即可获取网站真实ip。
5、理想zmap法
首先从 apnic 网络信息中心获取ip段,然后使用Zmap的 banner-grab 对扫描出来 80 端口开放的主机进行banner抓取,最后在 http-req中的Host写我们需要寻找的域名,然后确认是否有相应的服务器响应。
6、网络空间引擎搜索法
常见的有以前的钟馗之眼,shodan(https://www.shodan.io/),fofa搜索(https://fofa.so/)。以fofa为例,只需输入:title:“网站的title关键字”或者body:“网站的body特征”就可以找出fofa收录的有这些关键字的ip域名,很多时候能获取网站的真实ip。
7、F5 LTM解码法
当服务器使用F5 LTM做负载均衡时,通过对set-cookie关键字的解码真实ip也可被获取,例如:Set-Cookie: BIGipServerpool_8.29_8030=487098378.24095.0000,先把第一小节的十进制数即487098378取出来,然后将其转为十六进制数1d08880a,接着从后至前,以此取四位数出来,也就是0a.88.08.1d,最后依次把他们转为十进制数10.136.8.29,也就是最后的真实ip。
通过以上的方法,被获取到的ip可能是真实的ip、亦可能是真实ip的同c段ip,还需要要对其进行相关测试,如与域名的绑定测试等,最后才能确认它是不是最终ip。
所以,为了保护我们服务器,我们不好轻易暴露我们的真实ip,可以使用CDN、WAF等,在使用CDN的同时先确认ip历史记录中,是否存在你的真实ip,记得更换ip后再开启cdn。若网站有订阅邮件或发邮件的需求,可选择独立的服务器发取。子域名的ip记得隐匿,或者采取与主服务不同c段的服务器。
四、IP地址是什么?
关于IP的一些冷知识:
IP地址(本文中特指IPv4地址),是用于标识网络和主机的一种逻辑标识。依托于强大的TCP/IP协议,使得我们可以凭借一个IP地址,就访问互联网上的所有资源。
IP地址本质上,只是一个32位的无符号整型(unsigned int),范围从0 ~ 2^32 ,总计约43亿个IP地址。为了便于使用,一般使用字符串形式的IP地址,也就是我们平常用到的192.168.0.1这种形式。实际上,就是把整数,每8个二进制位转换成对应的十进制整数,以点分隔的形式使用。
比如,192.168.0.1和3232235521是等价的。

当今全球,互联网系统共分为四大区域,每一个区域都由一件互联网的本体,通过光缆覆盖信号。这四大区域分别被命名为:格兰芬多,斯莱特林,赫奇帕奇以及拉文克劳……

这是《爱情公寓3》中的一个让人捧腹的桥段。虽然是恶搞,但是有一件事儿说对了,互联网确实是分区域的。
全球共有五个区域互联网注册机构(RIR),分别是:
美洲互联网号码注册管理机构(American Registry for Internet Numbers,ARIN);
欧洲IP网络资源协调中心(RIPE Network Coordination Centre,RIPE NCC);
亚太网络信息中心(Asia-Pacific Network Information Centre,APNIC);
拉丁美洲及加勒比地区互联网地址注册管理机构(Latin American and Caribbean Internet Address Registry,LACNIC);
非洲网络信息中心(African Network Information Centre,AfriNIC)。
IP地址的划分,有RIR机构来进行统筹管理。负责亚洲地区IP地址分配的,就是APNIC,总部位于澳大利亚墨尔本。
各大RIR机构都提供了关于IP地址划分的登记信息,即whois记录。可以在各大RIR机构提供的whois查询页面上查看,或者使用whois命令查询:

whois信息中,会显示IP地址所属的网段,以及申请使用和维护这个网段的运营商。比如,上面的信息中显示,153.35.93.31隶属于江苏省联通。
某些黑客题材的电影中往往会出现使用whois直接查询得到了一个IP的位置,非常精确地定位到了一幢建筑物里。
这张截图来自于2015年上映的《BlackHat》,满满的槽点,都是导演YY出来的。
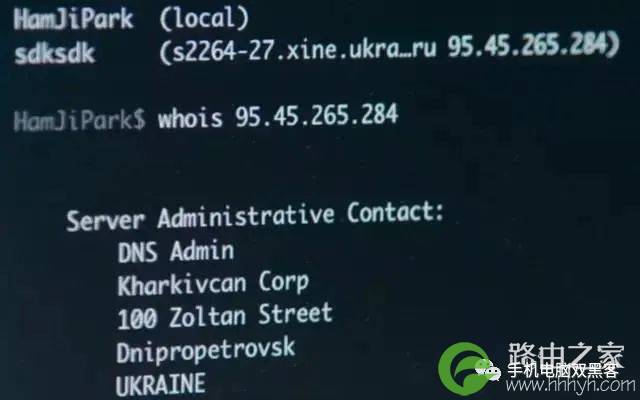
(导演:怪我咯?)
正餐之前,给大家稍加科普一下,下面我们就要进入主菜了。让我们逐一来解惑文章开篇提到的三个问题。
这个IP在哪儿?
前面提到IP的whois信息,其中包含了申请使用该IP的运营商信息,并且在网段描述信息中,会包含国籍和省份信息。
但是这样远远不够,风控场景中,我们需要更加精确的结果,需要知道这个IP具体在哪个城市、哪个乡镇,甚至希望能够精确到某一条街道或者小区。
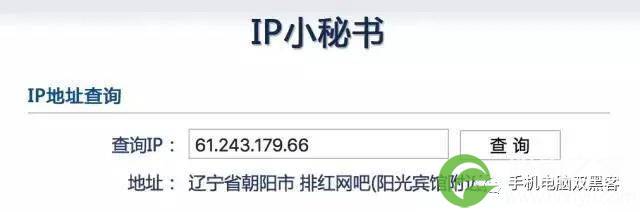
曾有人问:我们的IP地址库是否能够提供这样的结果?可以确定用户在某个网吧、写字楼甚至某个小区?
那上面这样的IP数据库是如何产生的呢?
俗称“人海战术”。您可别不相信,直到今天,依然有众多的网友在为这个IP库提供数据更新,上报IP地址的确切位置。但我们无从考证这个位置信息是否真实准确,如果不能报保证数据的准确性,在风控决策中同盾是不会去使用的。
一种IP地址定位手段,是通过海量Traceroute信息来分析。
理论上,如果我能够得到所有IP相互之间Traceroute的信息,就可以绘制出整个互联网的链路图。
(上图来自于IPIP.NET提供的BestTrace工具)
每一次traceroute,都会返回详细的网络链路信息。积累了足够多的链路信息之后,就可以直观地看出,很多链路都经过了同一个IP,那么这个IP就是骨干节点或者区域的骨干节点。先确定出哪些节点是CN2骨干节点,进一步确定省级骨干节点,再逐一识别市县区级的骨干节点,最后得到全国范围内的网络分布。
以下是CAIDA的一份报告,使用了类似的原理,但统计的最小单位是AS(自治域)

圈的边缘,就是探测节点,中间的红色部分,就是全球互联网的骨干节点。原理虽然简单,但实现起来却没那么容易。
首先,你得有足够数量的节点来探测、收集traceroute链路数据。其次,要有可靠的技术手段来及时分析探测到的结果,汇总形成IP地址数据库。据了解,DigitalElemet也用了类似的方式进行探测,在全球范围内一共部署了超过8万个探测节点。
根据这种网络链路探测的出的定位结果,业内又称之为“网络位置”。就是从互联网的结构上来说,我们最终确定了一个IP,被分配到了某个地方的运营商手里。
但是我们又遇到了很多其他的情况,给大家举几个简单的例子。
117.61.31.0 江苏省 南京市 电信
通过分析这个IP关联的所有定位数据,得到了如下的分布:
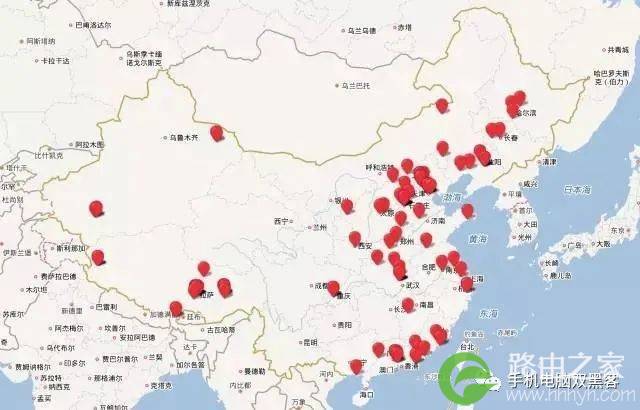
这种情况,我们称为“流量回源”。当用户在使用南京电信的手机卡上网时,无论用户身处哪里,他的流量都会回到南京电信,再转发出去,所以从IP上看,都会显示为一个南京的IP。
上面的定位信息分布,可以在RTB Asia的IP地址实验室中https://ip.rtbasia.com/
153.35.93.32 江苏省 南京市 联通
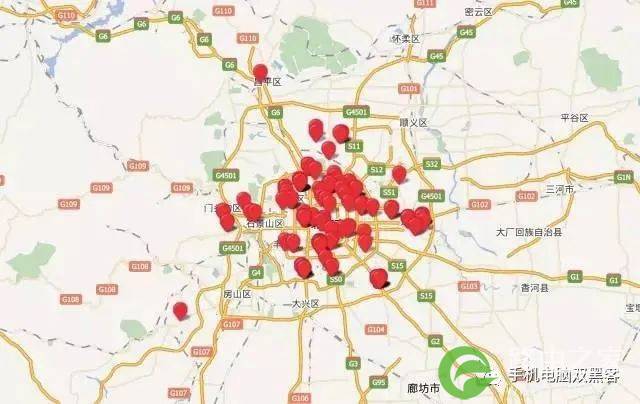
各种渠道的信息表明,这个IP确实分配到了南京联通,结果定位点全部落在了北京市的范围内。如果我们根据IP的定位结果来判断用户当前的位置,得到的结果肯定就错了。
难道前面提供的信息错了?其实是由于国内运营商对IP地址的划分和使用不透明,甚至特殊形式的租赁,导致北京的用户,分配到了一个南京的IP。
IP地址跨城市覆盖,覆盖范围非常大,用户位置和网络位置不在同一个城市甚至不在同一个省,都会影响到结果,无法准确给出判断。
另一方面,随着移动设备的普及,在用户允许的情况下,可以通过移动设备采集到设备上的GPS信息。前面大家看到的两张定位分布图,就是分析一个IP在历史上关联过的所有GPS定位绘制出来的。每一个红点,都表示曾经有一个用户这里出现过。再通过聚类和GPS反向解析,就可以预测一个IP下的用户,可能出现的地理位置。这个结果,我们又称之为“行为位置”。
这种分析方法看起来效果非常不错,但是却面临两个很重要的问题。
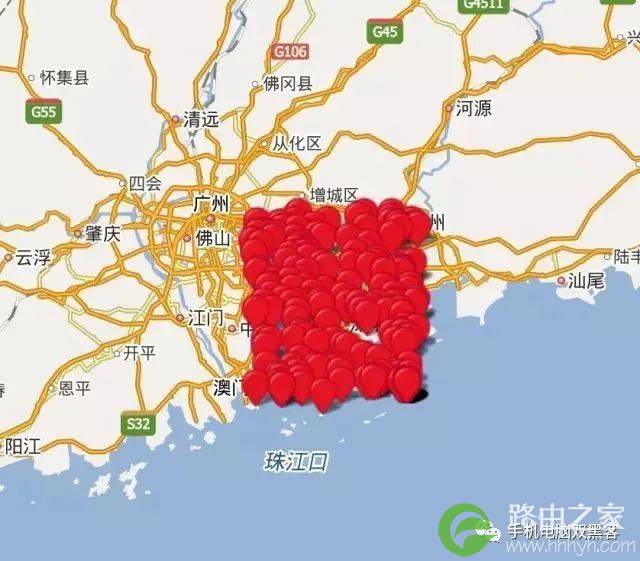
其一是,今年来设备作弊的方式层出不穷,如果没有有效的手段来保证数据的准确性和可靠性,最终得出的结果也会有偏差。
比如下面这里例子,定位点非常规整地分布在一个矩形区域内,而且覆盖到了海面上,做了深入的分析之后才发现这个IP下面有大量的作弊行为:
另一方面,依靠定位点分布来分析IP的定位,需要长时间积累GPS数据。人口密集的地方,这个数据积累可以只要一天,二线城市需要一周,三线城市就需要至少一个月了。此前还遇到一个位于塔克拉玛干沙漠中的基站IP,至今还没有过与之关联的GPS信息。如果某一天,IP地址被重新分配了,划分到另外一个城市去使用,就需要等上一周甚至一个月的时间,才能重新校正结果。而网络链路的分析可以很快感知到。
实际的使用中,我们会把这两种方式结合到一起。并不是说,两个定位结果中,有一个错了。两个都是正确答案,只是某些情况下,有一个答案并不适合风控场景。
互联网,就像物流系统一样。我们分析IP的位置,和分析一个快递小哥负责派送的区域原理是一样。没有哪个快递小哥只给一户人家送货,IP也一样,我们最终只能确定这个IP后面的用户,可能出现的地理位置区域。随着技术的提升,数据的积累,我们能够不断缩小这个范围,达到最贴近真实的结果。
国内的一个数据库,能够给出部分IP地址的精确定位,可以定位到某个学校、酒店甚至网吧。
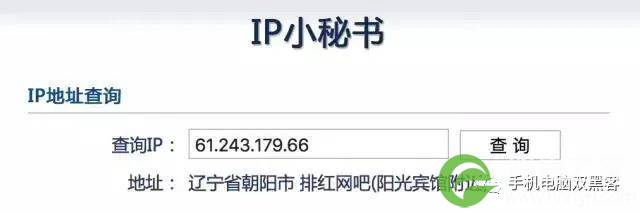
虽然这份依靠人海战术堆积起来的IP地址库在准确性和时效性上无法满足业务需求,但它也反映出了我们对IP地址研究的期望。我们除了想要知道这个IP的精确位置,我们也希望能够知道IP属主或者类别的信息。
这个IP是什么?
数据分析从来都不是盲目的。在开始之前,我们需要事先确定把IP地址划分为哪些类型。
网吧、酒店、学校、商场、企业,这种分类实际上是IP属主的类别划分。在不能准确判断IP属主的情况下,这样分类显然是不合适的。
从风控的角度看,我们对IP进行分类,实际上是为了能够优化风控规则。同一类的IP,风险往往会相同,就可以使用相同的风控策略。
比如,基站IP下用户数量非常大,这类IP上不能使用过于严苛的频次限制策略。
机房IP,比如阿里云、腾讯云、运营商数据中心等等。一般情况下,机房IP都会对应到某一台服务器上去。如果你发现某个用户是通过机房IP访问的,那么代理/爬虫访问的可能性很大。
此外,小运营商会通过租赁的方式,使用三大运营商的网络基础设施。他们所使用的线路,就会从机房IP列表中进行分配(机房IP是保证上下行带宽的,其他类型的IP,一般下行带宽高于上行带宽。专用出口使用机房的线路,可以保证足够的带宽。)
专用出口的IP,往往出现在机房IP的列表中,在不能准确排除专用出口IP的情况下,决不能轻易把机房IP拉黑。
比如下面的这个,根据网络位置判断,是广州市电信机房的IP。但是这个IP上的用户数量非常大,而且用户全部分布在广西境内。万一把这个IP拉黑了,投诉电话会被打爆的。
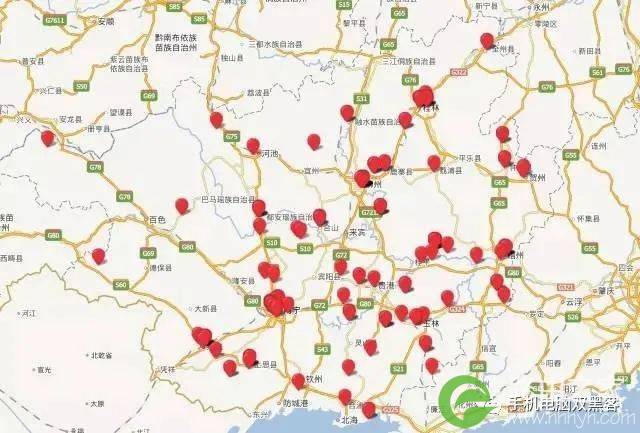
但机房恰恰是垃圾注册、刷单行为、代理行为、作弊行为和爬虫最密集的地方。如果能够准确地把专用出口这个类型识别出来,那么剩下的,就是具有较高风险的机房IP了。为此,我们根据IP地址上的用户行为特征、设备类型分布等信息来判断识别专用出口IP。
能否通过更多的用户特征来区分其他类型的IP呢?比如,判断一个IP是企业还是家用的宽带。
网吧、酒店、学校、商场、企业等等,这些类别,其实都是IP行为位置分析过程中的副产品。如果一个IP能够精确地定位到某一幢建筑物上,我们只需要判断这个建筑物是什么,就能得出结论。
一般的,企业的网络会使用专线,IP在很长的时间里都不会发生变化。随着定位数据的积累,行为位置就会呈现出密集性。
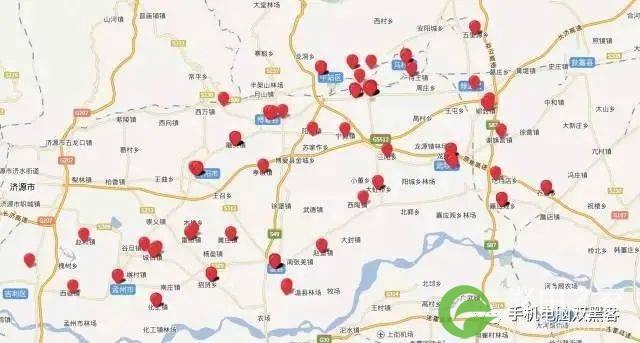
比如下面的这个IP:
定位点在途牛大厦附近聚集,可以确定这是途牛使用的一个固定IP。与之对应的,我们可以判断,通过这个IP上网的人,应该是途牛的员工。
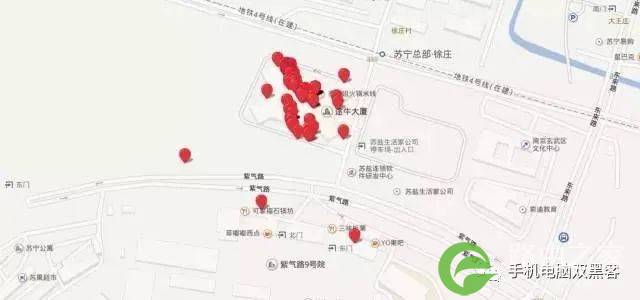
对于一般的家用宽带,虽然IP会频繁变化,但是在特定的一段时间里,IP会固定的出现在某个区域。
举个例子:
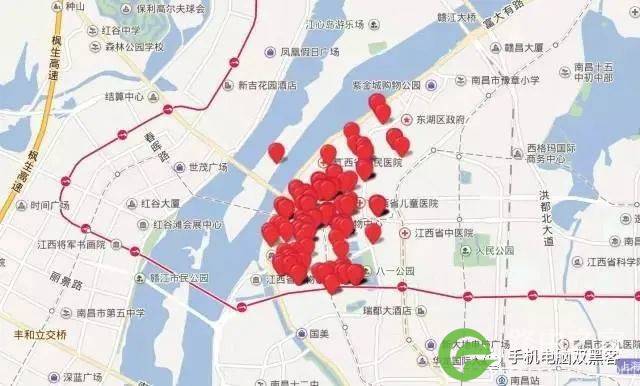
这个IP的定位点并没有像前面的例子那样在某一幢建筑物周围聚集,而是随机地分布在南昌市东湖区靠北的一片区域里。这是一个比较典型的家用宽带IP。
但IP只是业务系统的承载,IP定位的分布,会因为实际的业务而呈现出的聚集形式有非常大的差异。单纯通过定位信息的聚类分析,并不能满足所有IP地址的分类需求。
比如,中国邮政储蓄在某市的营业网点,使用专用线路,IP地址固定。每一个定位点的聚簇,都对应一个营业网点。
这个IP下的用户,除了营业网点的工作人员之外,还会有大量到营业厅办理业务的用户。
如果拥有足够的定位数据作为支撑,理论上是可以准确判断这些IP的属主的。
但是这种分析方法要求定位信息有比较高的准确性、时效性和数量级,可不是每家公司都有能力去尝试。
而且,中国范围内共有2.5亿活跃IP,一个月的时间里,平均每个IP会关联上万定位信息,然后做聚类分析。
这个数量级,光想想就觉得可怕……应该有更简单的办法才对。
为了讲解地更通俗易懂,这里援引《死亡笔记》中的一个片段。


根据作案时间的分布,推断出了作案者是一个学生(作者:都是因为老师布置的家庭作业太少了!)
我们分析IP的方法,和L的分析如出一辙。
如果一个IP是对应某家公司,这个IP下的用户行为,就会呈现出非常明显的工作日和工作时间的密集性,大家都是朝九晚五的上班族,都懂得哈~~
那么反过来,晚上6点以后,以及双休、节假日比较活跃的IP,就应该是普通的家用宽带。
此外,不同类型的IP,对应的用户数量会有所差异。
最简单的,一般基站的覆盖范围是3~5公里(可能存在多个基站公用同一个IP的情况),那么同一时间内,每个基站IP下面的用户数量可能会超过1~10万。而家庭宽带的IP,一般一个IP对应一户人家,人数在10人以内,某些小规模的营业场所,也会使用宽带的方式来提供网络连接,人数也会在100人以内。
根据这些特征,就可以把不同类别的IP逐步区分出来。最终,形成了今天我们同盾IP地址分类的全部:
教育网、基站、机房,目前都有比较完整的IP地址列表,通过简单的匹配就可以得出结论。
再根据用户的在不同时间段内的活跃情况,以及每个IP下的用户数量,我们能够准确判断出是家用宽带,还是企业的固定线路。
虽然到目前位置,我们的模型还不能准确区分一个IP到底是酒吧、网吧、酒店或者医院。但从风控的角度而言,我们目前的分类,已经满足绝大部分业务需求。
IP画像,是围绕反欺诈展开的,我们希望能够准确的评估一个IP地址的风险性,进而在风控策略中进行调控。
在IP画像设计初期,我们设计了一个风险评分,用于总体评价这个IP地址风险。风险分数中,IP是否有代理行为、是否命中已知的威胁情报、是否发生过风险行为,都作为评估的依据。但是这样的一个笼统的评分,在实际使用中却有诸多不便。
比如,我们曾经发现过一个IP地址,由于频繁的发生盗卡行为,最终我们给出的风险评分达到了94分(0~100,分数越高风险越高),然而这个IP下其他行为都是正常的,大量的正常用户通过这个IP进行登录、交易、支付等活动。
于是,我们萌生了一个想法,能否准确地定性一个IP到底做过什么样的坏事儿?
什么是坏事儿?
反欺诈中,涉及到的业务风险其实非常非常多。不同的行业、不同的平台都会有各自独有的一些风险。
就拿“黄牛”来说,随着互联网的发展,黄牛也从最早的票贩子,演变出了很多很多的花样。
案例1:在各大航空公司的网上订票渠道中,存在很多“占座黄牛”,他们通过特定的渠道,订购了一定数量的廉价机票,然后加价转售,甚至会高出这张机票原有的价格。如果不能及时出手,黄牛就会选择退票,导致飞机上出现很多空座位,各大航空公司对此也很头疼。转手的过程很简单,只需要修改乘机人即可,这个行为可以通过线上的数据分析发现出来。
案例2:一些票务网站(专指演唱会、赛事门票),黄牛会注册大量账号,抢购演唱会门票,拿到门票后,加价出手。由于黄牛拿到了实体票,转手过程是在线下进行的,通过线上行为就无法进行监控。但是,在抢票过程中,黄牛为了增加自己抢到票的几率,会使用很多个账号重复下单,大量订单中的收获地址都是同一个或者具有极高的相似度。
案例3:美团、猫眼、格瓦拉等购买电影票的平台中,也存在很大数量的黄牛。尤其是一些热门大片儿的首映票,价格可以炒到很高。电影票的黄牛,往往以代购的形式操作,他们拥有很高折扣的会员卡,可以低价购买到电影票,然后适当加价转手。黄牛完成支付后,拿到取票二维码,然后把二维码发送给买家。这个过程,也是很难通过线上的行为来进行检测的。
如果我们需要分析一个IP到底做了什么坏事,就必须要先给出明确的定义,到底什么样的行为算是坏事。然后把这些行为分解为非常详细的特征指标,进行建模。
这个过程是漫长的,就像上面举的例子,同样是“黄牛”,由于不同的平台,不通过的行业类型,中间存在着非常巨大的差异。每一种行为都要做这样的深入分析和研究,其实我们一开始是拒绝的……
在后来的一段时间里,我们团队接到了越来越多的提问,客户希望知道,这个IP到底干了什么?到底有没有风险?我们只能硬着头皮,去提取这个IP在过去半年里的行为数据,然后逐一分析。说到底,单凭一个IP地址的类型和地理位置,远远无法满足风控的需求。最终,我们决定要做这么件事儿。于是好几个月就这么过去了。
首先,我们梳理了一份反欺诈的词表,用来给出各种欺诈行为的明确定义。
风险行为
英文名称
定义
垃圾注册
Fraud Signup
使用虚假号码、通信小号、小号邮箱等容易获取且无法准确判定属主身份的信息进行注册。大部分垃圾注册是通过自动化工具进行的,垃圾注册产生的账号,会在后续的刷单、黄牛、薅羊毛、发布垃圾信息等活动中被使用。
褥羊毛
Econnoisseur
指那些坚持以最低的价格购买到最高品质的简明消费者。看起来是个褒义词,但是这类用户,为了能够多次享受新用户的优惠,会使用虚假号码、作弊工具的等手段来注册大量的垃圾账号,实际上并不能给平台带来任何的活跃用户
刷单
Brushing
通常所说的刷单,其实包括了两种:平台或商户,雇佣虚假的顾客进行购物,产生大量的虚假交易,进而提升平台或商铺的排名。另一种,大量用户在平台或商铺进行促销活动的时候涌入,以低价购买大量的商品,然后倒卖。
黄牛
Scalper
黄牛是指在合法销售途径以外 垄断、销售限量参与权或商品,并以此牟利的中介人。这样的定义直接涵盖了前面提到的多种黄牛行为
撞库
Collisionattack
攻击者通过收集互联网上泄露的用户数据,整理出每个账户的密码列表,针对性地使用这些帐密信息尝试登陆不同的网站。撞库过程中,登陆请求数量巨大,而且超过90%的登陆请求会失败。账号和密码呈现出一对多的关系,但是密码一般在10个以内。
暴力破解
Brute Force
对特定的账户或者多个账户进行密码尝试。暴力破解过程中,登陆请求数量很大,大部分也是登陆失败。但和撞库攻击相区别,暴力破解中,出现的账号数量较少,每个账号对应的密码数量都会非常大(从几百到几万都有可能)
短信轰炸
SMS Bombing
通过多次请求某一个或多个不同的短信验证码接口,向指定的手机号发送验证码短信,导致对方手机在一定时间内无法正常使用。短信轰炸在数量上会呈现出巨大的差异,集中在某一个时段爆发。请求总量可能达到上百万次。
垃圾信息
Spamming
发送不受欢迎(针对用户和平台)的内容。发送的过程一般是批量的,通过脚本或机器人来实现。发布垃圾信息,需要有大量的账号作为前提,这些账号往往通过垃圾注册或者撞库来获取。
……
……
……
上面的列表中,是同盾反欺诈词典中一小部分,列举了一些对互联网公司来说最为常见的风险行为。
那么,接下来的问题就是要逐一对这些风险行为进行取样,分析其中的行为特征。
特征提取
篇幅有限,这里就简单介绍一下我们对黄牛(票务行业)做行为分析和建模的过程。
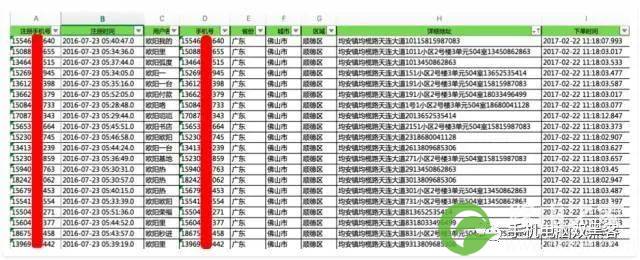
上图中,是我们抽取到的一份较为典型的黄牛抢票记录。
从这些记录里,能获取到怎样的信息呢?
1、这批账号都在同一天注册,并且注册时间较为集中,注册时间间隔大约为30秒;
2、每个账户只下一个订单,但是多个订单产生的时间非常接近,时间间隔仅为毫秒级;
3、多个订单中的收货人姓名很相似,直观判断,不太可能是真实的姓名;
4、多个订单中的收货地址有明显的异常,在末尾添加了无用的字符串;
5、收获地址末尾的字符串为11位的数字,比较像手机号,多个订单中的这个字符串相同;
6、账号注册和风险发生,中间存在较长的时间,可以定义为休眠账号或养号行为。
如果对这个地址做检查,我们会发现:广东省佛山市均安镇均榄路天连大道是真实存在的。
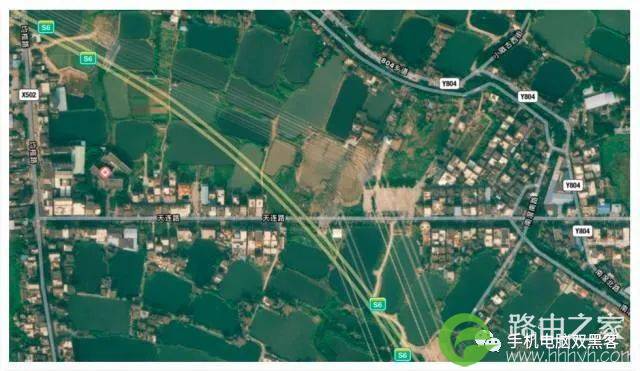
但是这附近并没有什么小区,反而更像是一个村子。也就是说,收货地址中,“天连大道”之后的部分都是随机添加的,可能并没有任何意义。
这样的做法,是为了避免平台对收获地址做校验,如果大量订单都寄送到同一个收获地址,那么这些订单都存在刷单的嫌疑。
上面的地图中,你可能也注意到了,其实并没有“天连大道”和“天连路”,其实是同一条街。但是由于名称不同,在地址核验过程中,就有可能被认为是两个不同的地址。类似的,比如“南京市白下区李府街”和“南京市秦淮区李府街”,也是同一条街道,2014年白下区被撤销,整体并入秦淮区。从行政区划上看,白下区已经不存在了,但是物流和快递大哥都知道,整个南京市就那么一条李府街,货物也可以成功地递交到收货人手中。
为此,我们也建立了一套用于对收货地址做真实性核验的系统,用于判断多个地址,是否指向了同一个地点。
除了前面列举的三个特征之外,还有一个比较隐蔽的特征,就是注册这些账号的手机号,其实都是”虚假号码“(参见:互联网黑产剖析——虚假号码)。换句话说,提交这些订单的用户,其实都是通过垃圾注册产生的垃圾账户(虚假账户)。除此之外,通过设备指纹技术,我们也识别出,这些订单其实都来自于同一台PC。从IP维度上,虽然每个订单的来源IP都不相同,但是每个IP都最终被确认为代理或者机房。
以上种种,就成为我们判断黄牛行为的特征,归纳如下:
1、黄牛会事先通过垃圾注册准备一批可用的账号,注册过程中往往会使用虚假号码;
2、账号注册过程中会出时间、IP、设备上的集中性,即同一个设备,同一个IP上注册了大量账号;3、多个订单中的收货人、收货地址不真实或相似度极高;
4、多个订单可能从同一个设备上产生;
5、提交订单的IP地址,大部分是机房IP或者代理IP;
6、垃圾账号注册完成之后可能不会立即进行抢票,而是经过了较长的沉睡期或进行特定的养号活动……
进一步细化之后,得到具体的指标参数,就可以进入训练模型的阶段了。
攻击链路
攻击链路(aka Kill-Chain),是安全领域中一个讨论比较多的话题。任何一次风险,都不会平白无故地发生,而是会有一个过程。对一次风险的定义,可以从最终的结果进行定义,但是更多的往往是对这个风险过程的定义。
以偷窃为例,一定会有这么几个步骤:
寻找目标 — 蹲点 — 标记 — 作案准备 — 撬门/扒窗 — 进入房间 — 寻找保险箱 — 撬开保险箱 — 拿走钱/珠宝 — 清理现场 — 离开现场 — 销赃 — 寻找下一个目标。
上面的这些,就是Kill-Chain中的节点(Node),也可以叫做风险过程(Process)。在整个攻击链路中,只有起点和终点是确定的,剩下的部分,可能会没有,也可能因为各种突发情况而产生分支链路忽然中断,或者重复某些环节。多个攻击链路,会在特定的一个节点上汇聚,这个节点,就成为了风险防控的关键节点。在这个节点上进行防护,效果就会比较好。
欺诈风险,也是一样的。前面分析黄牛的特征中,我们提到了黄牛会使用一批垃圾账号进行下单。分析一个账号的欺诈行为,需要纵观这个账号的整个生命周期,或者在既定的时间片内,关联上下文,看用户的行为在每一个环节中是否符合特定风险的特征。
那么,针对黄牛风险,攻击链路就可以表示如下:
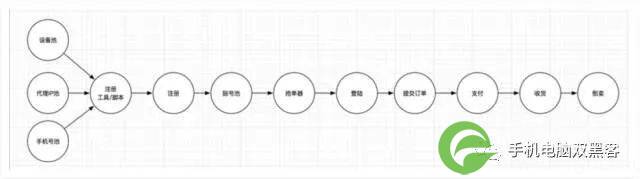
在攻击链路中,越是靠前的节点,发现和识别越为困难,因为各种特征其实并不明显,只能判断本次事件有嫌疑,而不能确定具体的风险。但是在这些环节上进行防护,起到的效果是最为显著的,成本也相对要低很多。
越是靠后的节点,发现和识别变得简单,很多特征都比较明显,但是防护就变得困难。并且,由于攻击链路本身会产生很多分支,可能在其他环节上已经产生了,即便是同一批次注册的垃圾账号,可能会在不同的场景中被使用。
此外,某些节点上会产生大量的分支链路,比如垃圾注册。通过注册工具/脚本,批量产生的垃圾账号,可能在后续的多种业务场景中出现,不同的业务场景中,又有着不同的风险。
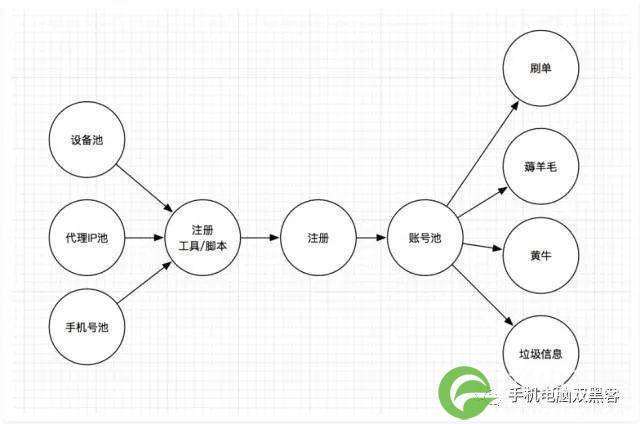
平台的业务越丰富,这个分支就会变得越发明显。如果一个平台同时提供了电商、电影票、团购、点评等多种线上业务,那么这个攻击链路就会变得非常复杂。
这也是为什么我们要建立IP地址画像、手机号画像和设备画像的原因。通过已知的各种风险行为,建立模型,通过跨平台、跨行业来进行联防联控,只要这个手机号、IP或者设备在历史上发生过一次风险行为,就会被识别出来,并且打上标记。
在整个攻击链路最开始的地方进行防护,并且在账号的整个生命周期中,进行持续监控,使得最终能够造成风险的账户数量降至最低。
在对抗中进步
这场欺诈和反欺诈的对抗,已经持续了多年,并且还将继续下去。
我们在不断提升检测能力、改进检测方式的同时,欺诈分子也在不断地产生新的作弊手段。并且,互联网在不断地寻求创新,同样是促销活动,在不同的平台上,会有截然不同的呈现方式,业务流程也不尽相同。这对我们分析风险行为,提取特征带来了极大的困难。
一旦新的业务模式产生,欺诈分子也会相应地寻找可供利用的业务逻辑缺陷,甚至产生一些新的风险类型。这需要我们不断地观察、学习和改进。为此,我们引入了无监督模型来辅助完成大量的指标提取工作。即使欺诈分子使用了新的技术、新的手段,特定风险的攻击链路是不会改变的,无监督模型可以从中提取出新的异常指标,再对模型进行优化和迭代。
我们识别出的每一次风险行为,都会作为标签,标记在手机号、IP和设备上。即使欺诈分子不断地更换这些信息,也总会被发现出来。这是同盾跨行业、跨平台联防联控的巨大优势,也是我们对抗欺诈行为的有力武器。
这些标签,目前在IP画像中已经可以使用,随着我们研究的进一步深入,越来越多的模型被开发出来,可以准确识别的风险行为也越来越多,力求让欺诈分子无所遁形。
本文来自投稿,不代表路由百科立场,如若转载,请注明出处:https://www.qh4321.com/18879.html